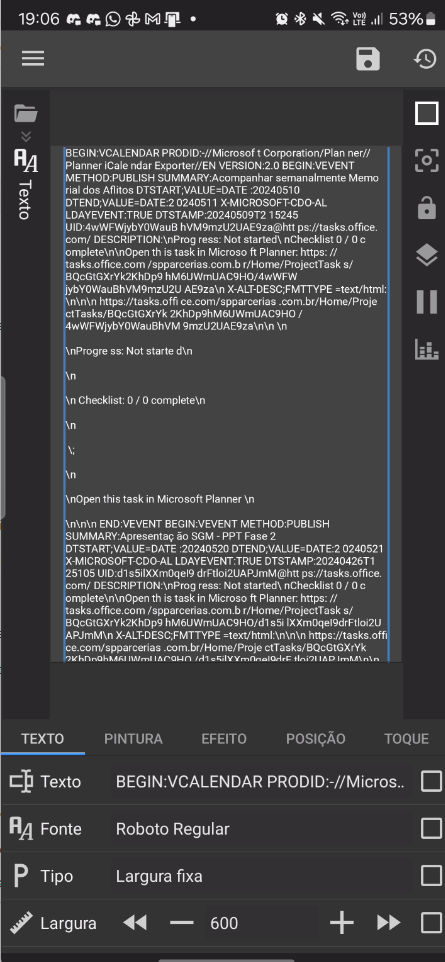
And I get “Desired text here” as output. But when I use the regex function with the WebGet function, I don’t get the desired text. Maybe is the HTML formatting, but I can’t find out how to fix it. See the whole formula and the URL:
Exactly, I need the “A validar com SEGES na próxima reunião”, that is the title of the task from MS Planner. It’s between SUMMARY and DTSTART. Not sure if it’s those line breaks characters that Kustom REGEX doesn’t read…
Regexp on multi line text is hard, i havent tried myself but you could check flows, with flows you can split this into multiple jobs, so maybe you can first use a regexp to find the right starting position and THEN split the text using another function to get the title
This seems to work for me granting there is a fixed number of items that you need to extract from that file. For simplicity, I placed the webget into a global variable.
If it isn’t asking too much, how did you download the file, from the link that I shared, and see its content? In Chrome, when I open the link, the empty page shows nothing. Saving it with CTRL + S as HTML or TXT also doesn’t give me anything.
EDIT: Forget it. Opening with Opera gives me the ics file.