Hmm… I am afraid that AccuWeather implements an anti-scraping system for their web data. And we can only get their weather data by using their paid API access.
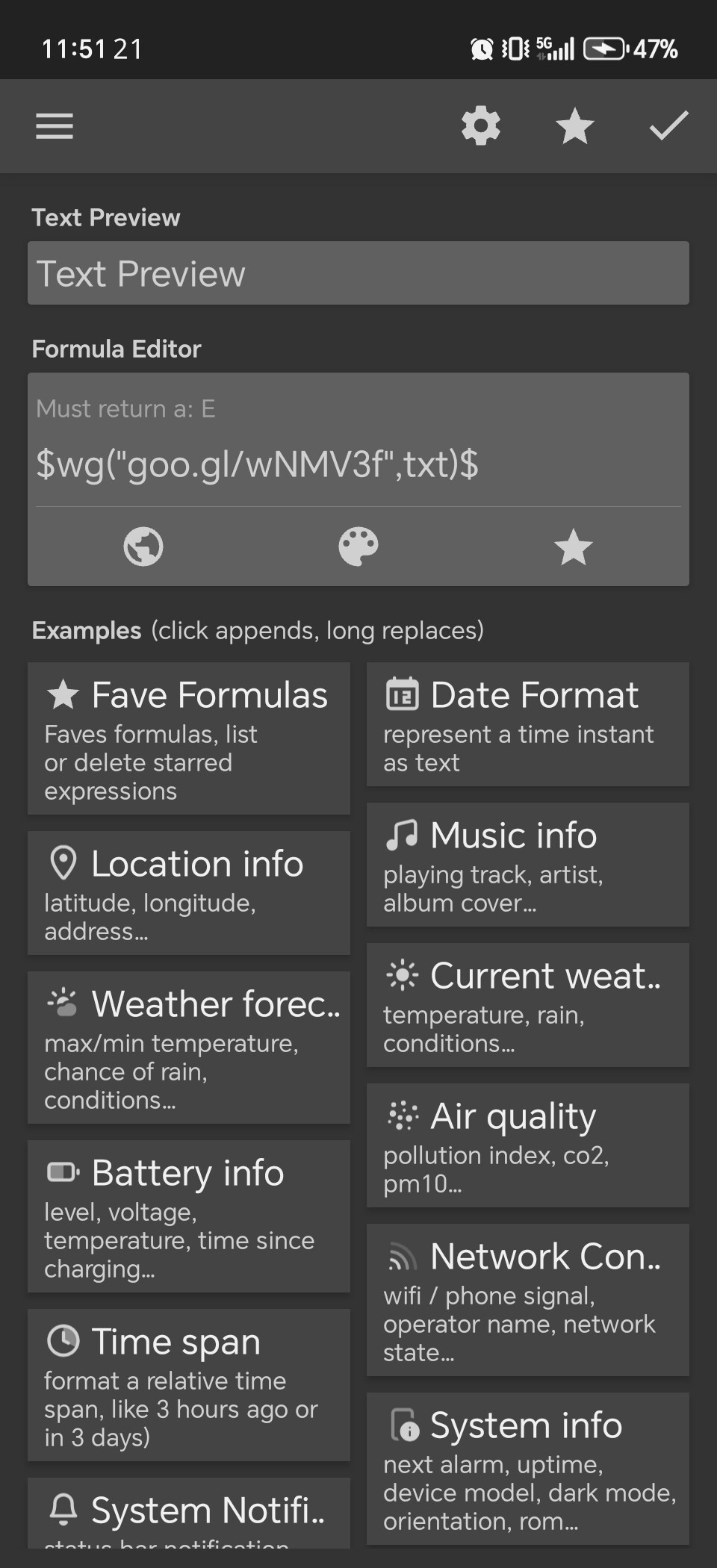
The wg() function of Kustom does well, I tried it on some other websites and RSS feeds. I personally use it in most of my interactive wallpaper products.
As for AccuWeather, they protect their website from web scraper. The only way to get their data is through API, you can use wg() to access their API URL if you subscribe to their API access.
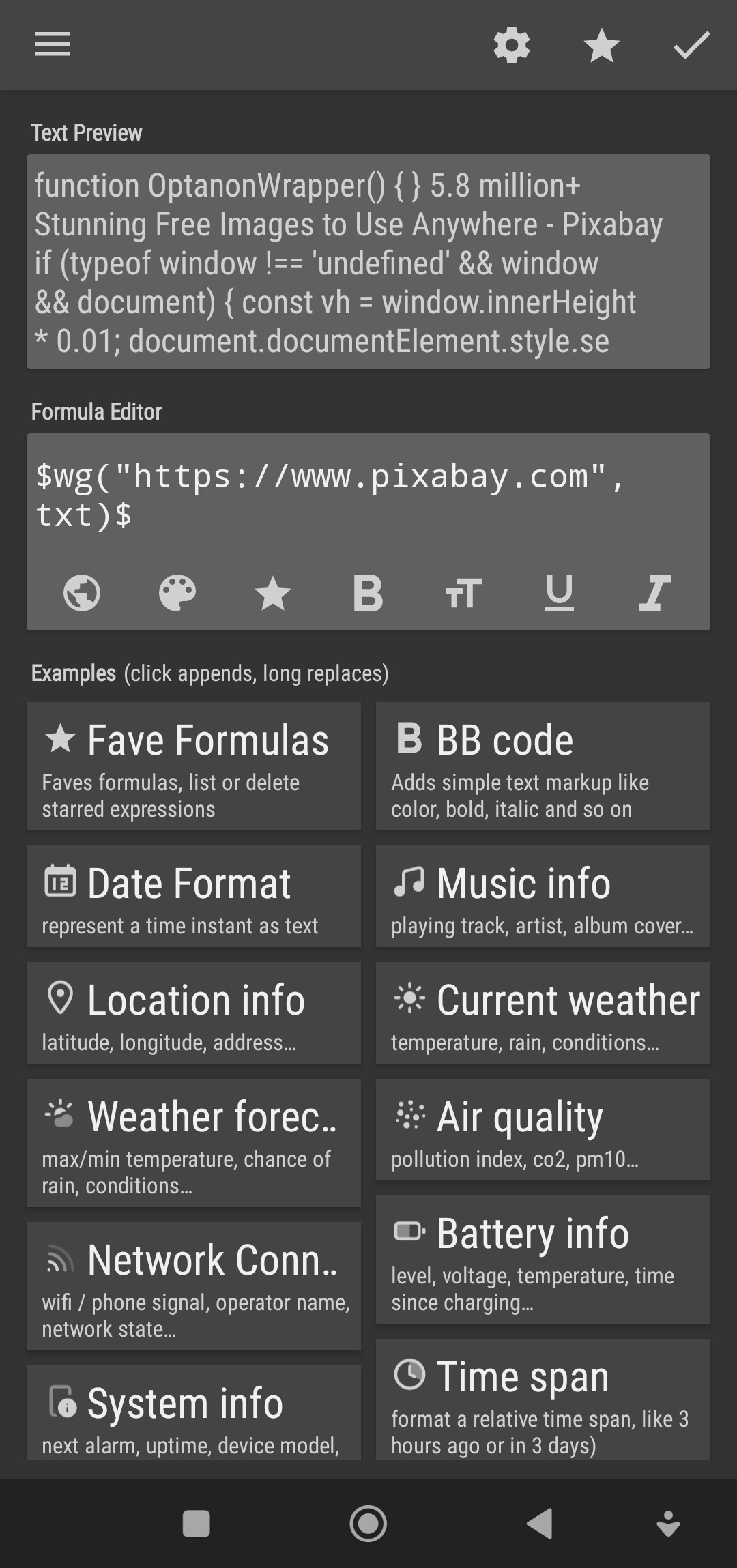
I just tried another website successfully:
$wg("https://www.amazon.com",txt)$
So, there’s no issue with wg() function, the issue is the target website (the URL)… whether the website allows anyone to scrap their web data or not.