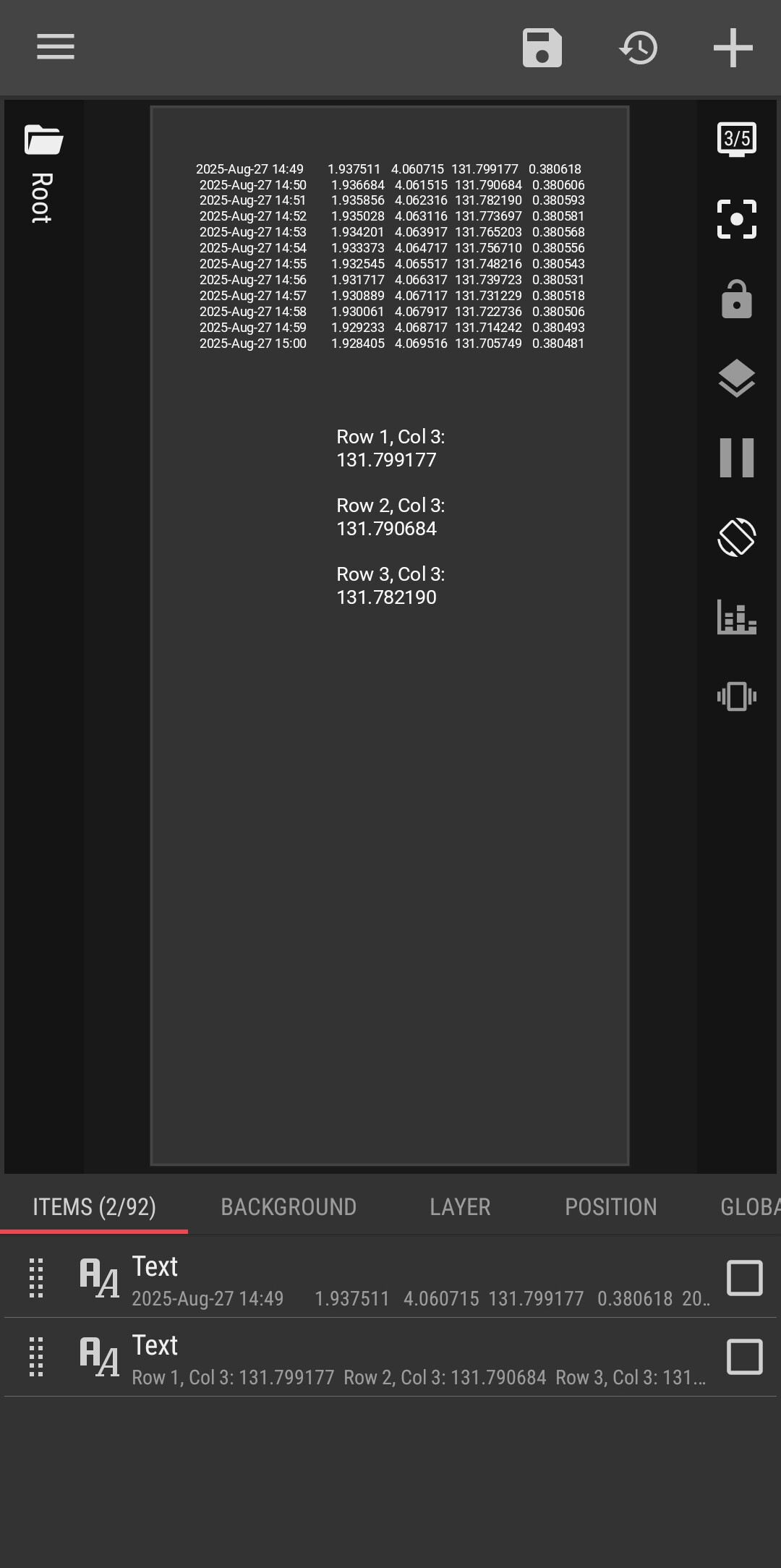
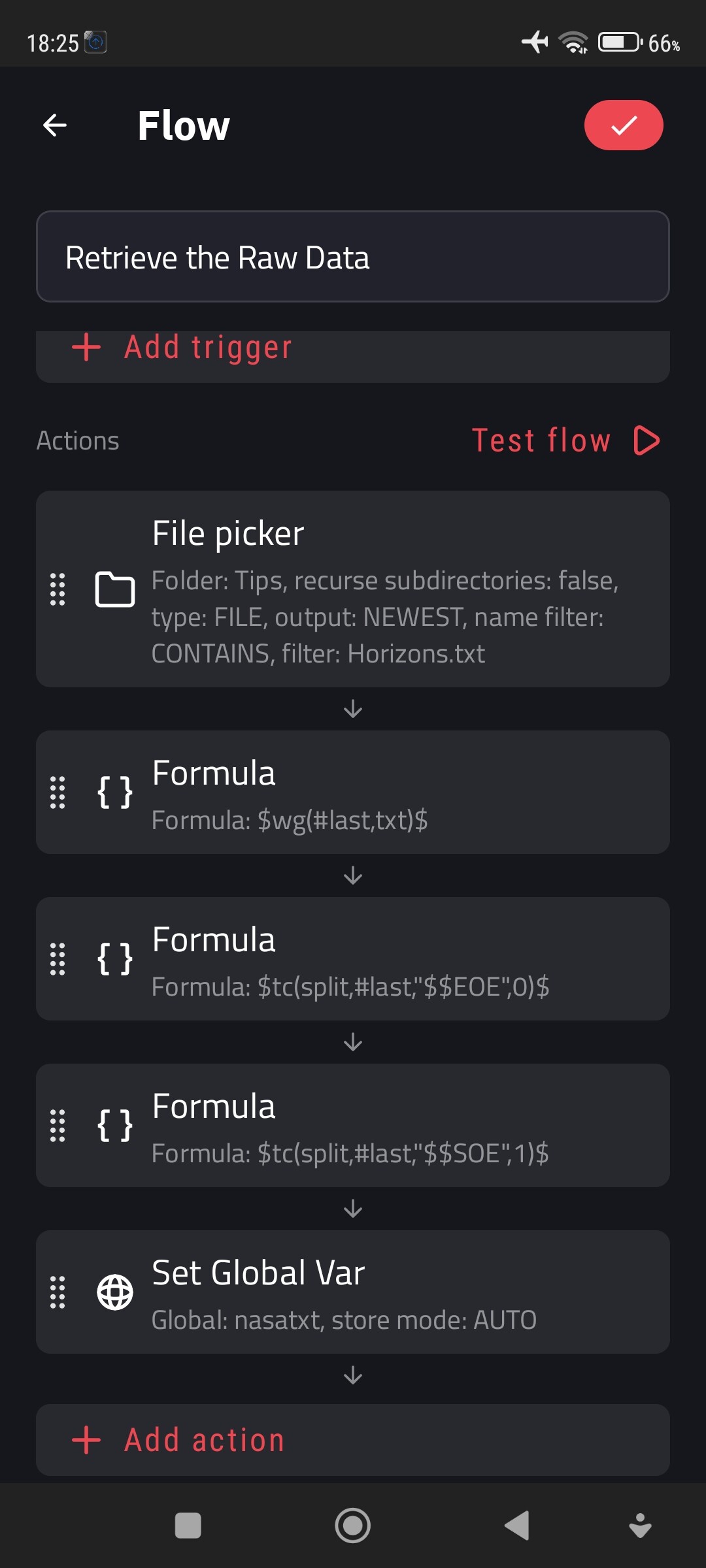
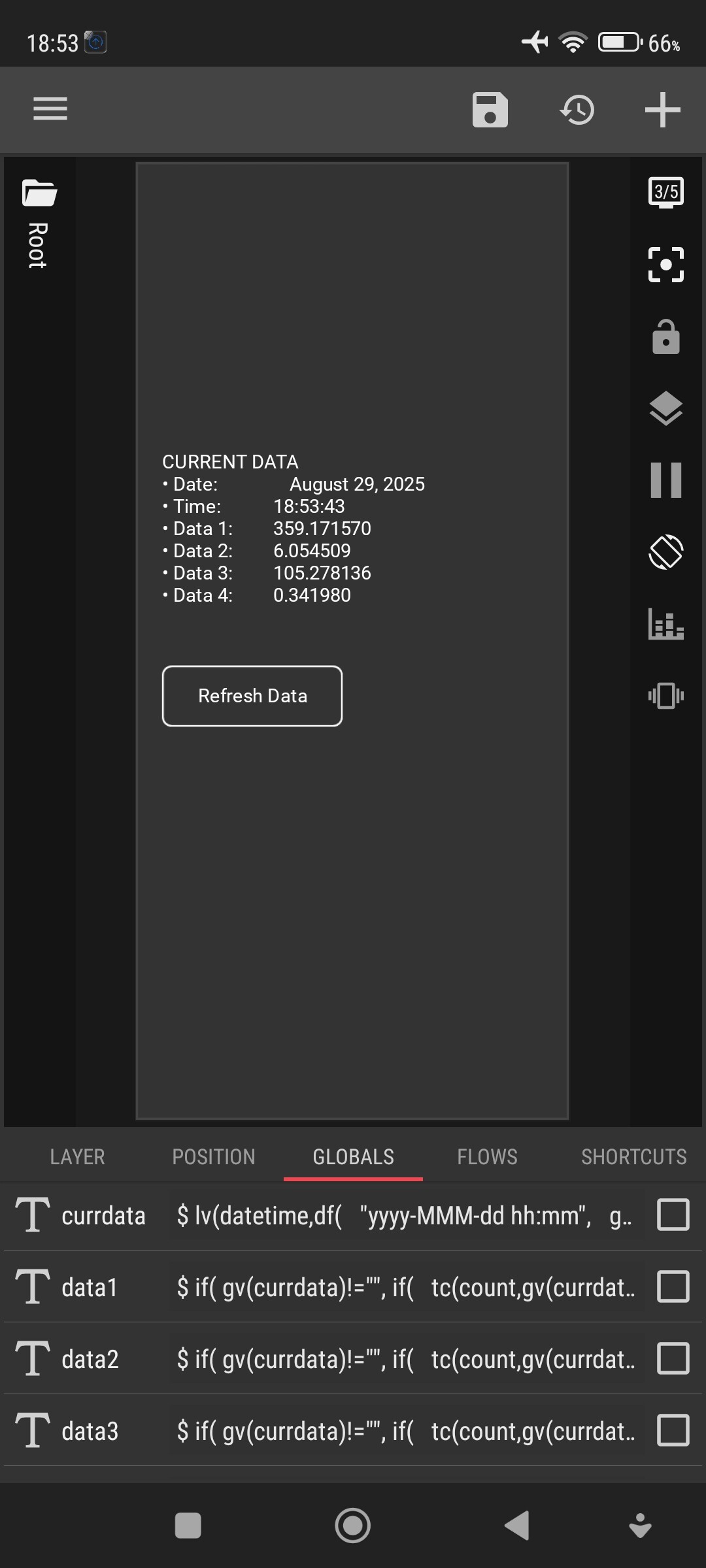
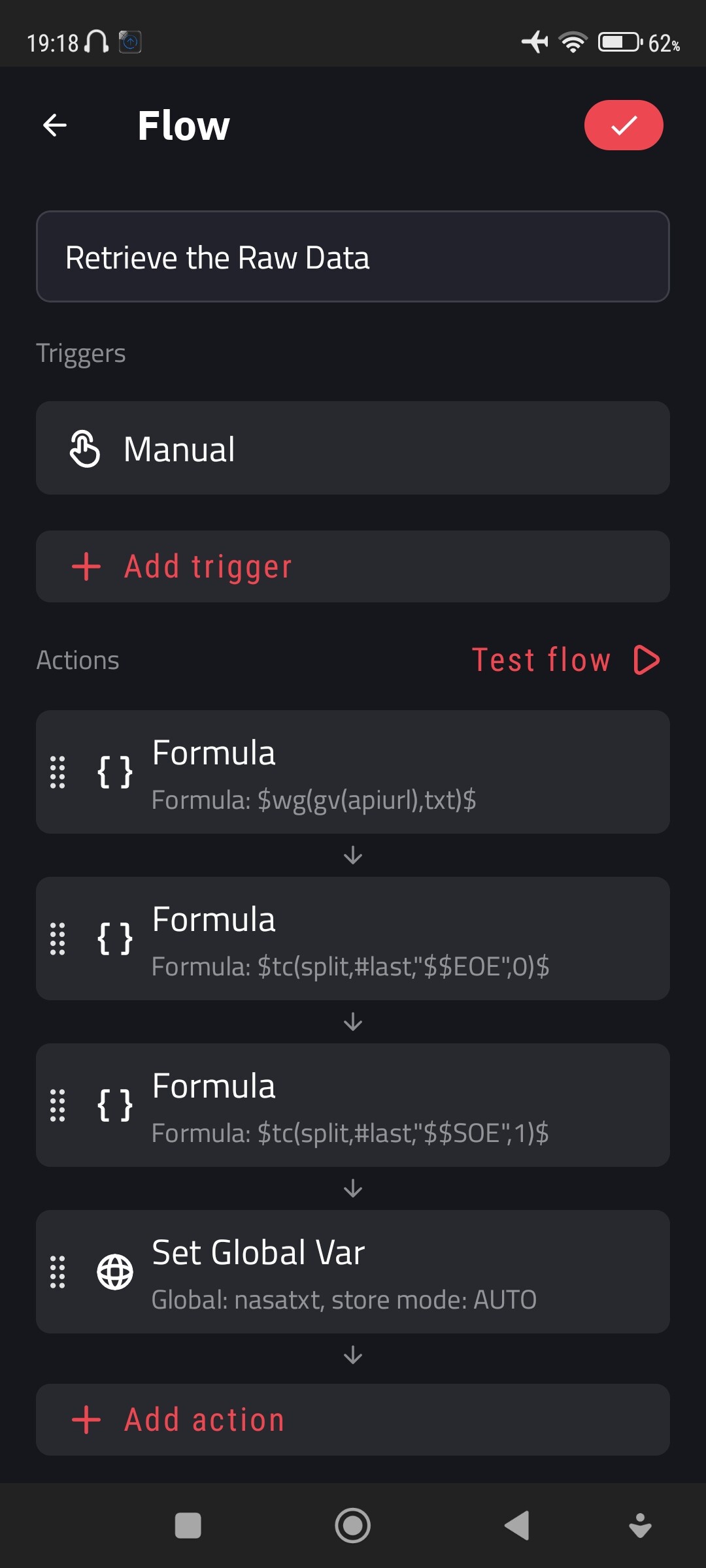
I have this part of a text in a global variable ‘nasatxt’:
...
2025-Aug-27 14:49 1.937511 4.060715 131.799177 0.380618
2025-Aug-27 14:50 1.936684 4.061515 131.790684 0.380606
2025-Aug-27 14:51 1.935856 4.062316 131.782190 0.380593
2025-Aug-27 14:52 1.935028 4.063116 131.773697 0.380581
2025-Aug-27 14:53 1.934201 4.063917 131.765203 0.380568
2025-Aug-27 14:54 1.933373 4.064717 131.756710 0.380556
2025-Aug-27 14:55 1.932545 4.065517 131.748216 0.380543
2025-Aug-27 14:56 1.931717 4.066317 131.739723 0.380531
2025-Aug-27 14:57 1.930889 4.067117 131.731229 0.380518
2025-Aug-27 14:58 1.930061 4.067917 131.722736 0.380506
2025-Aug-27 14:59 1.929233 4.068717 131.714242 0.380493
2025-Aug-27 15:00 1.928405 4.069516 131.705749 0.380481
...
Codes suggested by ChatGPT and Gemini do not work:
$tc(reg, gv(nasatxt), "2025-Aug-27 14:56\s+(\S+)\s+\S+", "$0")$
$fl(tc(split, gv(nasatxt), "\n"), "i", "if(i ~ """ + "2025-Aug-27 14:56" + """, i, """")")$
Ultimately, I would like to extract the 4 numbers on each line separately, and dynamically with a
df(yyyy-MMM-dd HH:mm)
Can anyone point me to a correct way of doing this?